Perceptron simple
El Perceptrón dentro del campo de las redes neuronales tiene dos acepciones. Puede referirse a un tipo de red neuronal artificial desarrollado por Frank Rosenblatt.Y dentro de la misma teoría de Frank Rosenblatt. También puede entenderse como la neurona artificial y unidad básica de inferencia en forma de discriminador lineal, es decir, un algoritmo capaz de generar un criterio para seleccionar un sub-grupo, de un grupo de componentes más grande. La limitación de este algoritmo es que si dibujamos en un plot estos elementos, se deben poder separar con un hiperplano los elementos "deseados" de los "no deseados". El perceptrón puede utilizarse con otros perceptrones u otro tipo de neurona artificial, para formar redes neuronales más complicadas.
El modelo biológico más simple de un perceptrón es una neurona y viceversa. Es decir, el modelo matemático más simple de una neurona es un perceptrón. La neurona es una célula especializada y caracterizada por poseer una cantidad indefinida de canales de entrada llamados dendritas y un canal de salida llamado axón. Las dendritas operan como sensores que recogen información de la región donde se hallan y la derivan hacia el cuerpo de la neurona que reacciona mediante una sinapsis que envía una respuesta hacia el cerebro, esto en el caso de los seres vivos.
Una neurona sola y aislada carece de razón de ser. Su labor especializada se torna valiosa en la medida en que se asocia a otras neuronas, formando una red. Normalmente, el axón de una neurona entrega su información como "señal de entrada" a una dendrita de otra neurona y así sucesivamente. El perceptrón que capta la señal en adelante se entiende formando una red de neuronas, sean éstas biológicas o de sustrato semiconductor (compuertas lógicas).
El perceptrón usa una matriz para representar las redes neuronales y es un discriminador terciario que traza su entrada  (un vector binario) a un único valor de salida
(un vector binario) a un único valor de salida  (un solo valor binario) a través de dicha matriz.
(un solo valor binario) a través de dicha matriz.
(un vector binario) a un único valor de salida (un solo valor binario) a través de dicha matriz.
Donde 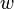 es un vector de pesos reales y
es un vector de pesos reales y 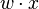 es el producto punto (que computa una suma ponderada).
es el producto punto (que computa una suma ponderada). 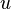 es el 'umbral', el cual representa el grado de inhibición de la neurona, es un término constante que no depende del valor que tome la entrada.
es el 'umbral', el cual representa el grado de inhibición de la neurona, es un término constante que no depende del valor que tome la entrada.
es un vector de pesos reales y es el producto punto (que computa una suma ponderada). es el 'umbral', el cual representa el grado de inhibición de la neurona, es un término constante que no depende del valor que tome la entrada.
El valor de (0 o 1) se usa para clasificar como un caso positivo o un caso negativo, en el caso de un problema de clasificación binario. El umbral puede pensarse de como compensar la función de activación, o dando un nivel bajo de actividad a la neurona del rendimiento. La suma ponderada de las entradas debe producir un valor mayor que para cambiar la neurona de estado 0 a 1.
(0 o 1) se usa para clasificar como un caso positivo o un caso negativo, en el caso de un problema de clasificación binario. El umbral puede pensarse de como compensar la función de activación, o dando un nivel bajo de actividad a la neurona del rendimiento. La suma ponderada de las entradas debe producir un valor mayor que para cambiar la neurona de estado 0 a 1.
En el perceptrón, existen dos tipos de aprendizaje, el primero utiliza una tasa de aprendizaje mientras que el segundo no la utiliza. Esta tasa de aprendizaje amortigua el cambio de los valores de los pesos.1
El algoritmo de aprendizaje es el mismo para todas las neuronas, todo lo que sigue se aplica a una sola neurona en el aislamiento. Se definen algunas variables primero:
el 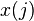 denota el elemento en la posición
denota el elemento en la posición  en el vector de la entrada
en el vector de la entrada
denota el elemento en la posición en el vector de la entrada
el 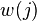 el elemento en la posición en el vector de peso
el elemento en la posición en el vector de peso
el elemento en la posición en el vector de peso
el  denota la salida de la neurona
denota la salida de la neurona
denota la salida de la neurona
el 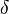 denota la salida esperada
denota la salida esperada
denota la salida esperada
el  es una constante tal que
es una constante tal que 
es una constante tal que
Los dos tipos de aprendizaje difieren en este paso. Para el primer tipo de aprendizaje, utilizando tasa de aprendizaje, utilizaremos la siguiente regla de actualización de los pesos: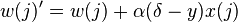
Para el segundo tipo de aprendizaje, sin utilizar tasa de aprendizaje, la regla de actualización de los pesos será la siguiente: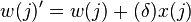
Por lo cual, el aprendizaje es modelado como la actualización del vector de peso después de cada iteración, lo cual sólo tendrá lugar si la salida difiere de la salida deseada . Para considerar una neurona al interactuar en múltiples iteraciones debemos definir algunas variables más:
difiere de la salida deseada . Para considerar una neurona al interactuar en múltiples iteraciones debemos definir algunas variables más: denota el vector de entrada para la iteración i
denota el vector de entrada para la iteración i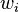 denota el vector de peso para la iteración i
denota el vector de peso para la iteración i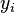 denota la salida para la iteración i
denota la salida para la iteración i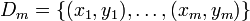 denota un periodo de aprendizaje de
denota un periodo de aprendizaje de  iteraciones
iteraciones
En cada iteración el vector de peso es actualizado como sigue:
Para cada pareja ordenada  en
en
en
Pasar 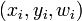 a la regla de actualización
a la regla de actualización 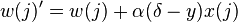
a la regla de actualización
El periodo de aprendizaje  se dice que es separable linealmente si existe un valor positivo
se dice que es separable linealmente si existe un valor positivo  y un vector de peso tal que:
y un vector de peso tal que: 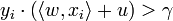 para todos los
para todos los  .
.
se dice que es separable linealmente si existe un valor positivo y un vector de peso tal que: para todos los .
Novikoff (1962) probo que el algoritmo de aprendizaje converge después de un número finito de iteraciones si los datos son separables linealmente y el número de errores está limitado a: 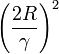 .
.
.
Sin embargo si los datos no son separables linealmente, la línea de algoritmo anterior no se garantiza que converja.
Ejemplo
Considere las funciones AND y OR, estas funciones son linealmente separables y por lo tanto pueden ser aprendidas por un perceptrón.


La función XOR no puede ser aprendida por un único perceptrón puesto que requiere al menos de dos líneas para separar las clases (0 y 1). Debe utilizarse al menos una capa adicional de perceptrones para permitir su aprendizaje.

http://es.wikipedia.org/wiki/Perceptr%C3%B3n
Enviar por correo electrónicoEscribe un blogCompartir con TwitterCompartir con FacebookCompartir en Pinterest
Las Redes Neuronales son un campo muy importante dentro de la Inteligencia Artificial. Inspirándose en el comportamiento conocido del cerebro humano (principalmente el referido a las neuronas y sus conexiones), trata de crear modelos artificiales que solucionen problemas difíciles de resolver mediante técnicas algorítmicas convencionales.
En esta página web trataremos de acercar al visitante a este tema, mostrando las bases neurológicas y matemáticas, los principales modelos vigentes y ejemplos interactivos que solucionan algunos problemas de forma eficaz.
LA NEURONA BIOLÓGICA
Fue Ramón y Cajal (1888) quién descubrió la estructura celular (neurona) del sistema nervioso. Defendió la teoría de que las neuronas se interconectaban entre sí de forma paralela, y no formando un circuito cerrado como el sistema sanguíneo.
Una neurona consta de un cuerpo celular (soma) de entre 10 y 80 mm, del que surge un denso árbol de ramificaciones (dendritas) y una fibra tubular (axón) de entre 100 mm y un metro.
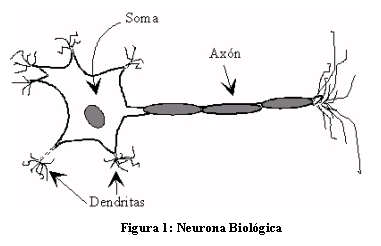
De alguna forma, una neurona es un procesador de información muy simple:
· Canal de entrada: dendritas.
· Procesador: soma.
· Canal de salida: axón.
Una neurona cerebral puede recibir unas 10.000 entradas y enviar a su vez su salida a varios cientos de neuronas.
La conexión entre neuronas se llama sinapsis. No es una conexión física, si no que hay unos 2 mm de separación. Son conexiones unidireccionales, en la que la transmisión de la información se hace de forma eléctrica en el interior de la neurona y de forma química entre neuronas; gracias a unas sustancias específicas llamadas neurotransmisores.
No todas las neuronas son iguales, existen muchos tipos diferentes según el número de ramificaciones de sus dendritas, la longitud del axón y otros detalles estructurales. Sin embargo, como hemos visto, todas ellas operan con los mismos principios básicos.
MODELO DE NEURONA ARTIFICIAL
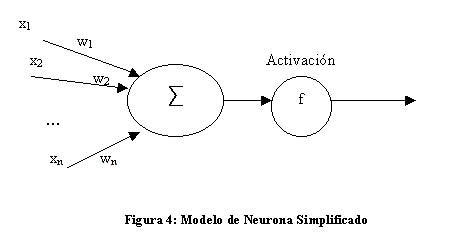
El modelo de Rumelhart y McClelland (1986) define un elemento de proceso (EP), o neurona artificial, como un dispositivo que a partir de un conjunto de entradas, xi (i=1...n) o vector x, genera una única salida y.
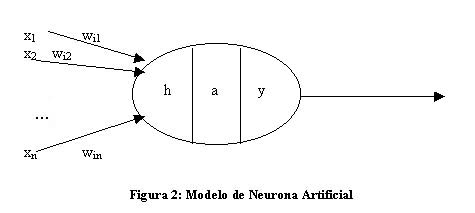
Esta neurona artificial consta de los siguientes elementos:
· Conjunto de entradas o vector de entradas x, de n componentes
· Conjunto de pesos sinápticos wij. Representan la interacción entre la neurona presináptica j y la postsináptica i.
· Regla de propagación d(wij,xj(t)): proporciona el potencial postsináptico, hi(t).
· Función de activación ai(t)=f(ai(t-1), hi(t)): proporciona el estado de activación de la neurona en función del estado anterior y del valor postsináptico.
· Función de salida Fi(t): proporciona la salida yi(t), en función del estado de activación.
Las señales de entrada y salida pueden ser señales binarias (0,1 – neuronas de McCulloch y Pitts), bipolares (-1,1), números enteros o continuos, variables borrosas, etc.
La regla de propagación suele ser una suma ponderada del producto escalar del vector de entrada y el vector de pesos:
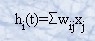
También se usa a menudo la distancia euclídea entre ambos vectores:
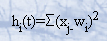
Existen otro tipo de reglas menos conocidas como la distancia de Voronoi, de Mahalanobis, etc.
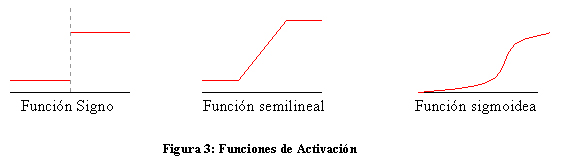
La función de activación no suele tener en cuenta el estado anterior de la neurona, sino sólo el potencial hi(t). Suele ser una función determinista y, casi siempre, continua y monótona creciente. Las más comunes son la función signo (+1 si hi(t)>0, -1 en caso contrario), la función semilineal y las funciones sigmoides:
La función de salida suele ser la identidad. En algunos casos es un valor umbral (la neurona no se activa hasta que su estado supera un determinado valor).
Con todo esto, el modelo de neurona queda bastante simplificado:
RED NEURONAL ARTIFICIAL
Una red neuronal artificial (RNA) se puede definir (Hecht – Nielssen 93) como un grafo dirigido con las siguientes restricciones:
Los nodos se llaman elementos de proceso (EP).
Los enlaces se llaman conexiones y funcionan como caminos unidireccionales instantáneos
Cada EP puede tener cualquier número de conexiones.
Todas las conexiones que salgan de un EP deben tener la misma señal.
Los EP pueden tener memoria local.
Cada EP posee una función de transferencia que, en función de las entradas y la memoria local produce una señal de salida y / o altera la memoria local.
Las entradas a la RNA llegan del mundo exterior, mientras que sus salidas son conexiones que abandonan la RNA.
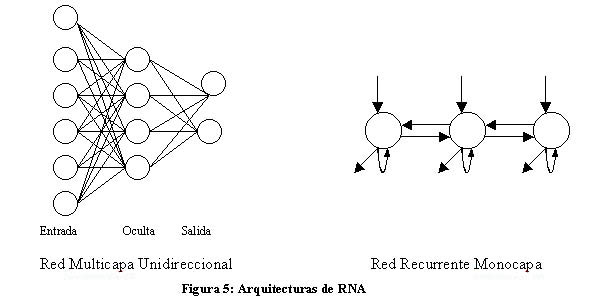
ARQUITECTURA DE LAS RNA
La arquitectura de una RNA es la estructura o patrón de conexiones de la red. Es conveniente recordar que las conexiones sinápticas son direccionales, es decir, la información sólo se transmite en un sentido.
En general, las neuronas suelen agruparse en unidades estructurales llamadas capas. Dentro de una capa, las neuronas suelen ser del mismo tipo. Se pueden distinguir tres tipos de capas:
· De entrada: reciben datos o señales procedentes del entorno.
· De salida: proporcionan la respuesta de la red a los estímulos de la entrada.
· Ocultas: no reciben ni suministran información al entorno (procesamiento interno de la red).
Generalmente las conexiones se realizan entre neuronas de distintas capas, pero puede haber conexiones intracapa o laterales y conexiones de realimentación que siguen un sentido contrario al de entrada-salida.
APRENDIZAJE DE LAS RNA
Es el proceso por el que una RNA actualiza los pesos (y, en algunos casos, la arquitectura) con el propósito de que la red pueda llevar a cabo de forma efectiva una tarea determinada.
Hay tres conceptos fundamentales en el aprendizaje:
Paradigma de aprendizaje: información de la que dispone la red.
Regla de aprendizaje: principios que gobiernan el aprendizaje.
Algoritmo de aprendizaje: procedimiento numérico de ajuste de los pesos.
Existen dos paradigmas fundamentales de aprendizaje:
Supervisado: la red trata de minimizar un error entre la salida que calcula y la salida deseada (conocida), de modo que la salida calculada termine siendo la deseada.
No supervisado o autoorganizado: la red conoce un conjunto de patrones sin conocer la respuesta deseada. Debe extraer rasgos o agrupar patrones similares.
En cuanto a los algoritmos de aprendizaje, tenemos cuatro tipos:
Minimización del error: reducción del gradiente, retropropagación, etc. La modificación de pesos está orientada a que el error cometido sea mínimo.
Boltzmann: para redes estocásticas, donde se contemplan parámetros aleatorios.
Hebb: cuando el disparo de una célula activa otra, el peso de la conexión entre ambas tiende a reforzarse (Ley de Hebb).
Competitivo: sólo aprenden las neuronas que se acercan más a la salida deseada.